This advanced module provides several advanced training protocols for different listening situations.
It differs from closed set phoneme recognition as there are no explicit choices for each trial. The
chance level is close to zero. There are six training groups in this module which target at different
listening conditions.
Group 1: Open Set Word Recognition Training
This group uses Open Set Recognition Training Protocols. While this training group uses the same training
materials (monosyllabic words) used in the closed set phoneme recognition training, there are no explicit choices
in this group. The user must select letters on the screen to identify the words. There are three training levels
including word recognition in quiet, in 10 dB SNR and in 0 dB SNR.
Group 2: Open Set Sentence Recognition Training
This group uses Open Set Recognition Training Protocols. It is similar to the open set word recognition training;
the user must type whole sentences or click the letter in the screen to select the whole sentence. The program
calculates the percentage of words correctly identified. There are three training levels in this group, including
quiet, 10 dB SNR, and 0 dB SNR. The interface is the same as that used for the word group.
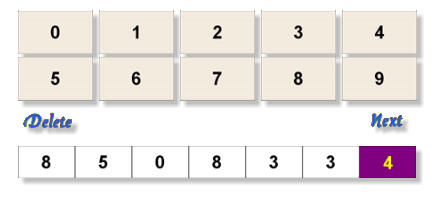
Group 3: Digit Recognition Training
This group uses both Open Set Recognition Training Protocols and Speech Synthesis based on Concatenation for
assessing/training the listener's digit span, or their ability to recognize the number of digits. The number of digits
per string ranges from 3 to 7 (3 digits, 5 digits, and 7 digits). The interface for this training group is displayed
below.
Group 4: Melody Notes Sequence Recognition Training
This group uses both Open Set Recognition Training Protocols and Speech Synthesis based on Concatenation.
This training group provides PIANO-based Melodic Sequence Recognition Training for CI patients to improve
recognization of musical melodies, thereby improving their music appreciation. This is an open set recognition
task. The sequence is random. Test stimuli were melodic sequences composed of 2, 3, 5, or 7 notes of equal
duration whose frequencies corresponded to musical intervals. The notes range from C4 to C5. The interface for
this group is shown below.
Group 5: Instrument Sequence Recognition Training
This training group provides Instrument Sequence Recognition Training for CI patients to improve to help
recipients improve their appreciation of music. This is an open set recognition task. The sequence is random. Test
stimuli were melodic sequences composed of 2, 3, 5, or 7 notes of equal duration whose frequencies
corresponded to musical intervals. This group uses both Open Set Recognition Training Protocols and Speech
Synthesis based on Concatenation. The main interface for this group is shown below.
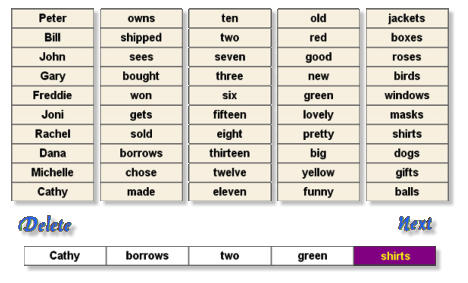
Group 6: Concatenated Sentence Recognition Training
The Concatenated Speech Training Protocols utilize sentences that include five words in the following order:
noun, verb, number, adjective, and noun. Each category includes 10 words providing a total of 100,000 random
sentences. The user selects the words from the screen (10x5) to produce the sentence. The program determines
the number of correct words and computes percentage points. Again, there are three training levels in this training
group, including quiet, 10 dB, and 0 dB. Here shows the interface for this training group.
Group 7: Recognition Threshold Training for Words, Sentences, Digits, and Concatenated Sentences
This group uses several Advanced Training Protocols including Open Set Recognition Training Protocols, Speech
Synthesis based on Concatenation, and Trial-based Adaptive Speech in Noise Training. The tasks in this group
are designed to assess/train the listener's ability to recognize words, sentences, or digits in the presence of
background noise. The background noise consists of six-talker speech babble. Speech recognition thresholds and
the signal-to-noise ratio will be measured. The digit string has 3 digits. The main interface is the same used for the
above groups.